Heeft een organisatie problemen bij het gebruiken van (cloud) applicaties? Dan kan ze altijd terecht bij Will Moonen. De Nivo-consultant legt uit hoe hij de vinger op de zere plek legt.
Of het nu een autofabrikant is, een Belgische netbeheerder van elektriciteit en aardgas of de Nederlandse ambassades wereldwijd: als ze moeilijkheden hebben in de cloud kloppen ze allemaal aan bij Will en Nivo. Soms omdat ze via via gehoord hebben dat ze bij hem moeten zijn en alvast contact opnemen, en soms omdat het water hen figuurlijk aan de lippen staat.
Voor Will is dat geen probleem. ‘Het leukste aan dit werk is dat ik tot nu toe altijd in staat ben gebleken om met een paar relatief eenvoudige verbeteringen een impasse te doorbreken en de zaak weer vlot te trekken. Wat het extra bijzonder maakt is dat het vaak om grotere, internationaal opererende organisaties gaat met de nodige cultuurverschillen – zeker bij de Nederlandse ambassades.’
Wat Will doet
Werken in de cloud heeft voor die bedrijven veel voordelen ten opzichte van een plaatselijk datacentrum, maar ook in de cloud treden er soms problemen op voor de gebruiker. Denk aan traagheid van het systeem of verbindingsproblemen. Gelukkig heeft Will een passende aanpak om die problemen te verhelpen.
‘Om daar wat aan te doen moet je eerst het probleem analyseren. Dat kan door data te verzamelen’, weet Will. ‘Op basis daarvan kom je tot een conclusie met een verbetervoorstel. En het idee is: als je dat voorstel uitvoert, is het probleem opgelost.’
Het analyseren
Even stapje terug. Hoe ziet dat verzamelen van data eruit? ‘We analyseren netwerkpakketjes die heen en weer fietsen tussen de gebruiker en de cloudapplicatie’, legt Will uit. ‘Hieraan zie je waar, wanneer en waarom het fout gaat.’
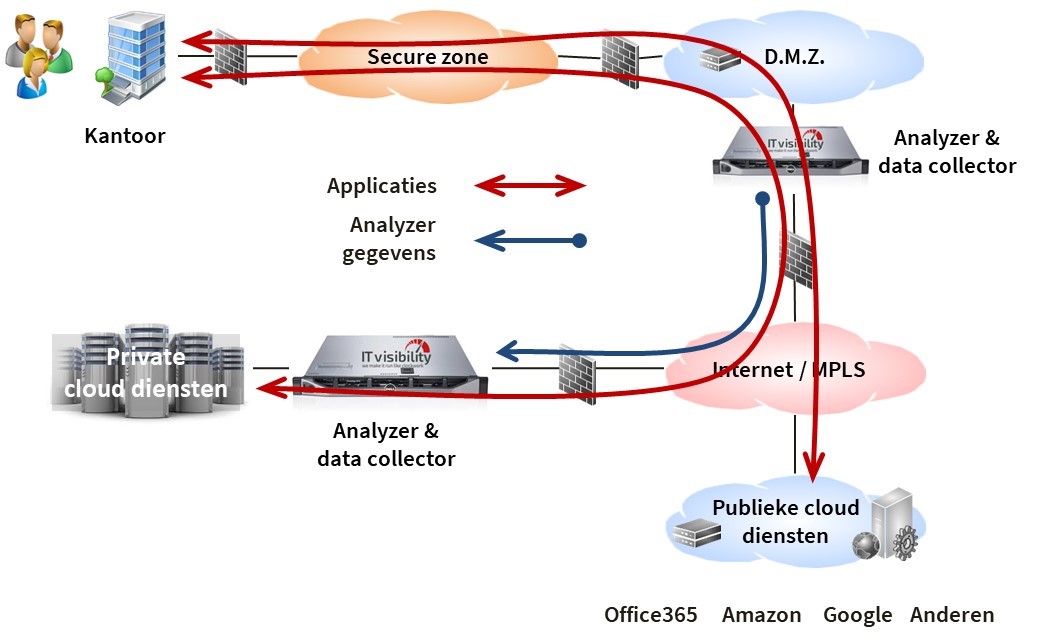
In bovenstaande afbeelding zie je hoe dat er in de praktijk uitziet. Will vertelt: ‘De rode pijl staat voor alle netwerkpakketjes van de applicaties zoals ermee gewerkt wordt door een gebruiker. Daarnaast zie je twee datacollectors, oftewel analyzers. Die verzamelen 24 uur per dag kengetallen. Dat zijn gegevens van alle inkomende en uitgaande netwerkpakketjes, de blauwe pijl. Op basis van deze gegevens is een foutanalyse mogelijk van alle gebruikers en alle applicaties.’
Een voorbeeld. ‘Soms ervaren gebruikers te weinig capaciteit aan de MPLS-kant, dat staat voor Multiprotocol Label Switching’, vertelt Will. ‘Aan de private datacenterkant zie je dan bijvoorbeeld dat servers veel te klein geschaald zijn of dat er veel te weinig opslagcapaciteit is, waardoor een server heel druk is. Dat zie je terug in de metagegevens die datacollectors verzamelen. Op basis daarvan kan je zien: dáár gaat het mis. Bij die applicatie of bij die server ligt het probleem.’
De afbeelding schetst de situatie voor de gebruikers van 1 kantoor. Maar de datacollector in het datacentrum doet dat voor alle gebruikers die van dat datacenter gebruikmaken en voor alle applicaties die daarbij horen. ‘Zo kun je in een heel kort tijdspad heel veel problemen analyseren. Om van daaruit verbetervoorstellen te doen. En dan hebben we binnen 4 tot 6 weken vaak substantiële oplossingen.’
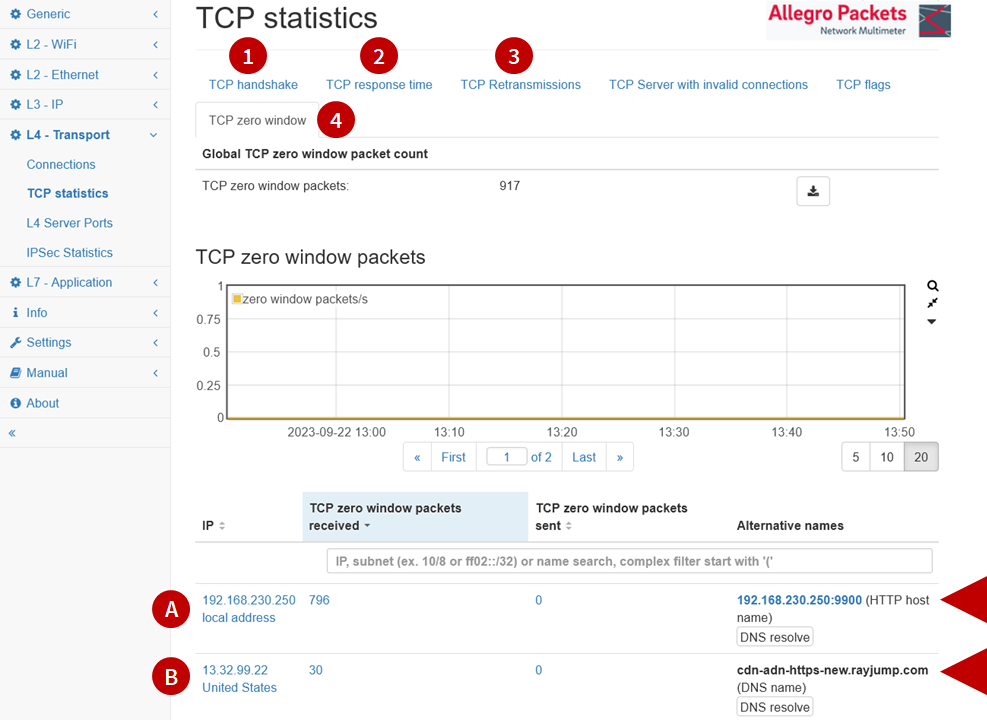
Opgehaalde data
En wat zie je dan als je al die data verzameld hebt? In bovenstaande afbeelding zie je de 4 belangrijkste KPI’s (Key Performance Indicator) bij een foutanalyse. Dat zijn:
• KPI-1: TCP handshake. Dat is de snelheid waarmee een verbinding tot stand komt.
• KPI-2: TCP response time. Dat is de snelheid waarmee het netwerk de gegevens verwerkt.
• KPI-3: TCP retransmissions. Dat is het percentage aan gegevens dat opnieuw verwerkt moet worden.
• KPI-4: TCP zero window packets. Dat is het aantal keren dat een systeem te weinig verwerkingscapaciteit had.
Will: ‘In de afbeelding zien we de grafiek van KPI-4. Die laat zien dat over de hele linie nauwelijks capaciteitsproblemen zijn. De twee systemen die er wél last van hebben, zijn aangeduid met A en B. Waarbij A een intern systeem is en B een systeem bij een cloud provider in de Verenigde Staten. De oorzaak van het probleem heeft dus te maken met Die 796 keren dat het interne systeem te weinig verwerkingscapaciteit had.
Waarom dit interne systeem te weinig verwerkingscapaciteit heeft, is nu nog niet bekend. Er kunnen vele oorzaken zijn.
TaaS is een mooie en effectieve tool om problemen boven tafel te krijgen. Beter is uiteraard het voorkomen van problemen. Dat start met werken onder architectuur. Daarbij is het inregelen van compliancy belangrijk, net als het regelmatig auditen op de life cycle services.
Will maakt deel uit van het franchise netwerk van Nivo. Als cloud / software architect voert hij diverse projecten uit. Troubleshooting as a Service komt voort uit Will’s drijfveer om een puzzel op te lossen waar anderen op stukgelopen zijn.